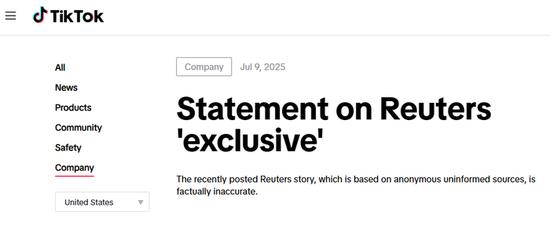
TikTok正开发仅面向美国用户的独立应用?TikTok回应

谷歌计划将 Gemini 并入 Deepmind,下个月开始生效

《风驰赛车手》今日首播 黄景瑜李治廷让教练头疼

几十个测试后,发现海螺语音与 ElevenLabs 掰手腕的能力不是盖的

AIGC:我不是元宇宙的附庸品

Andrej Karpathy 最新视频盛赞 DeepSeek:R1 正在发现人类思考的逻辑并进行复现

《英雄联盟:云顶之弈》庆祝6周年,云顶之弈时光机携专属玩家奖励回归

四川省新联会新文艺工作者专委会夏季工作会议在成都举行

通用3D机器视觉平台是不是伪命题?

孙晶晶惊艳千年花妖,于正《临江仙》定档开播

《京东618夏日歌会》众多实力歌手齐聚,共创视听盛宴

618解锁歌手同款音响——意大利多曼尼以声学重构专属你的空间叙事


Copyright © 2018-2023 观察观测站- 关注健康,享受独特内容 All Rights Reserved. XML地图 观察观测站- 关注健康,享受独特内容